AI KEIEI LIVE — 2026.04.06(月)
Claude Codeで第二の脳を構築|一人社長のAI経営術【戸野塚レン×ひろくん】
配信日: 2026年4月6日(月)13:00〜 / 出演: 田中啓之(ひろくん) × 戸野塚レン(れんくん)
家事と子育てのスキマで経営する3方よしAI共創コンサルタントの田中啓之、ひろくん(@passion_tanaka)です。
今回は、AI経営術LIVEの月曜13時コラボ配信を記事化してお届けします。ゲストは Claude Code 講座主宰・OpenCloud開発者の 戸野塚レン(れんくん)さん。テーマは「第二の脳をClaude Codeで構築する」。一人社長の AI経営を本気で考えるための対談LIVEです。
ひろくん(田中啓之)
3方よしAI共創コンサルタント / GPTs研究会主催 / 分身AI開発者。@passion_tanaka
れんくん(戸野塚レン)
Claude Code講座主宰 / OpenCloud開発者 / 株式会社IBEEST代表。「ロジックに体温、温かい未来を実装する」をコンセプトに24時間開発体制を構築。@ren_aivest
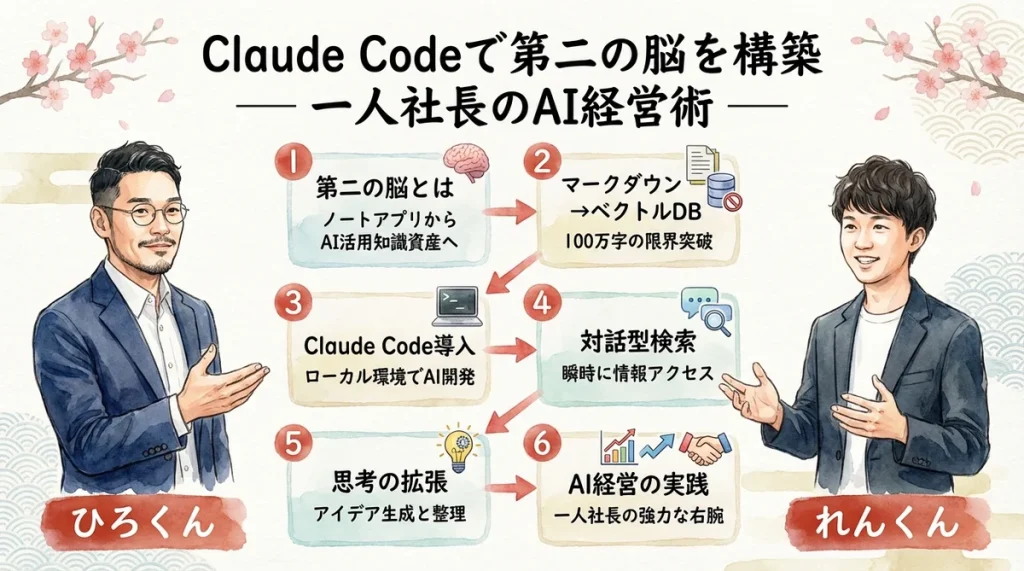
LIVEで話したこと
れんくんと「第二の脳」について話したよ。マークダウンが増えすぎてAIが重くなってきた体験、Claude Codeにリサーチエージェントを作らせてベクトルDB選定を任せた話、複数のRAGを横串で刺すと0→1のひらめきが生まれるかも——そんな問いかけが行き来した対談だった。
「第二の脳」とは何か
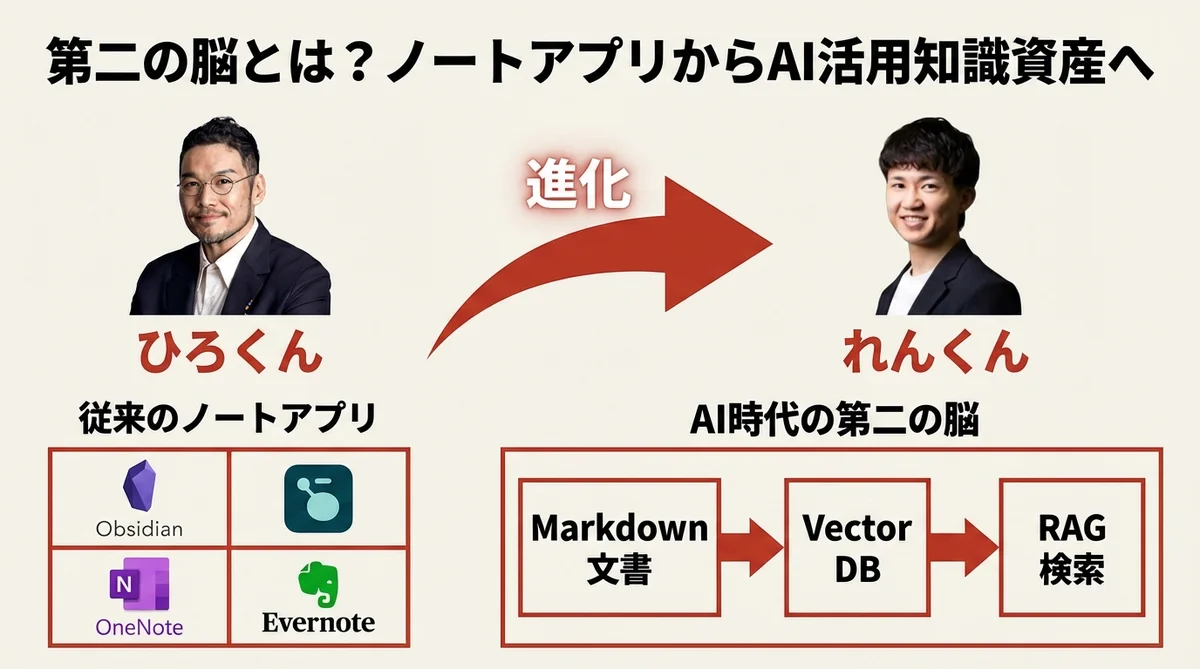
「第二の脳」という言葉を聞いたことがあるだろうか。エバーノートが流行した2010年代前後から、ナレッジマネジメントの世界ではよく使われてきた概念だ。しかし今、Claude Codeの登場によって、その意味は大きく塗り変わろうとしている。
私は長年、自分の考えや学びを言語化して保存してきた。紙のノートとペンから始まり、ワード、エバーノート、ワンノート、ログシーク、オブシディアン……記録するツールは変わっても、「自分の外に知識を蓄積する」という行為自体は変わらなかった。それが、AI時代に入って、新しい次元に突入した。
単に「記録する」から「AIが活用できる形で記録する」へ。この違いは、料理で言えば食材をただ冷凍庫に放り込むのと、きちんと下処理して分類して冷蔵庫に収納するとの差だ。どちらも「保存している」が、料理人(AI)が使いやすいのは明らかに後者だ。
れんくんは、この「第二の脳」の概念を、より具体的な技術レイヤーで整理している。ベクトルデータベース(RAG)を使い、テキスト情報をAIが検索しやすい形に変換することで、圧倒的な速度と精度でナレッジを引き出せるようになる。これは一人社長にとって、頭脳労働を根本から変える技術だ。
ひろくん
「マークダウンだけだと相当ヘビーになってきて、AIが下手れてくる。トークンも爆増してくる。だからベクトルのデータベースをClaude Codeで作って、設定してもらったのが今の形」
AI経営において「第二の脳」を持つとはどういうことか。それは、自分の発言・会議・学びのすべてをデータ資産に変え、いつでもAIが検索・参照できる状態にしておくことだ。これができていると、「あの時あいつに何て言ったっけ?」「前回のプロジェクトのやり取りはどうだったか?」が瞬時に引き出せる。
現代の一人社長は、意思決定の量が膨大だ。しかも、それを一人でやらなければならない。「覚えている」「覚えていない」という曖昧な記憶ではなく、蓄積された自分自身のナレッジが常にAIを通じてアクセス可能な状態にある。これが、AI時代の一人社長にとっての「真の第二の脳」だ。
れんくん
「Claude Codeに自分の情報を渡していくとき、テキストデータを毎日毎週毎月送り続けるのは、AIが読みにくい形になる。だからベクトルデータベースという、AIが検索しやすい形にまとめている」
「どこに何があるか把握できている料理人」と「食材が冷凍庫にただ積まれている状態」の差だ。同じ情報量でも、AIが活用できる形になっているかどうかで、アウトプットの質は天と地ほど違う。
私自身、分身AIの開発を4年ほど続けてきた。最初は「見た目の分身」から作り、次第に「中身の分身」へと深化させてきた。ナレッジ、共感ストーリー、コンテキストエンジニアリング。それが今、ハーネスエンジニアリングという概念へと進化している。第二の脳は、その土台となるものだ。
マークダウンからベクトルデータベースへ — AIが読みやすい形に変える
ひろくん(5:47〜)
「やり方ってどっかにまとめたかなちょっとねそれこそなんかねそのやり方を分身のAIチームにブログを書かせているのでこれ」

Claude Codeを使い始めると、まず多くの人がたどり着く場所がある。それが「マークダウンファイル(.md)」だ。CLAUDE.mdやSKILL.mdなど、AIへの指示を書いたファイルがどんどん増えていく。10個、50個、100個……ファイルが増えるほど、AIは「賢くなる」感覚がある。
しかし、落とし穴がある。マークダウンファイルの量が増えると、あるポイントからAIの動きが急激に重くなる。レスポンスが遅くなり、精度が落ち、トークンの消費が爆発的に増える。これは「AIが読みにくい形でデータを持っている」ことが原因だ。
れんくんは、この問題を非常にクリアに説明してくれた。マークダウンはAIにとって読めないわけではない。ただ、10万字、20万字、100万字という量になったとき、検索にかかるトークン消費が膨大になり、AIが「考えすぎて」しまう。あるいは「読みすぎてバカになる」という現象が起きる。
れんくん
「マークダウンファイルはAIが読みにくい形。10万20万100万文字となったとき、検索のトークン消費がものすごくて、AIが考えすぎたり、読みすぎてバカになったりするデメリットがある」
解決策が、ベクトルデータベース(ベクトルDB)だ。ベクトルDBとは、テキスト情報を数値(ベクトル)に変換して格納する仕組み。AIが検索しやすい形に変換されているため、膨大なテキストの中から必要な情報を素早く、かつ精度高く引き出せる。
ベクトルDB以前に私がたどり着いた中間解が、NotebookLMだった。すべての情報をNotebookLMに入れて、そこから引き出す形にしたら、確かに軽くなり精度も悪くなかった。しかしNotebookLMはクラウドサービスであり、ローカルで完結したい、自分のシステムの中でコントロールしたい、という思いがあった。
そこでたどり着いたのが、Claude Code自身にベクトルDBを作らせる、という発想だ。Claude Codeに「自分の現状のファイル量と種類を調べて、最適なベクトルDBを選んで、設定して」と指示する。これだけで、自分に合ったベクトルDBの構築が始まる。
ひろくん
「ベクトルのデータベースを逆にClaude Codeで作って、作ってから探して設定してもらった。NotebookLMは軽くて精度も悪くなかったが、やっぱりローカルの中でできたほうがいい」
ベクトルDBへの移行を考えたとき、最初に直面するのが「どのベクトルDBを使えばいいのか」という問題だ。Amazon、Google、Voyage AIなど、選択肢は無数にある。技術的な比較をするのは素人には難しい。しかしここに、Claude Codeを使う大きなメリットがある。選定作業そのものをAIに任せられるのだ。
マークダウンからベクトルDBへの移行は、一度やれば完了ではない。ビジネスが成長し、情報が増えるにつれ、データベースの運用設計も進化させていく必要がある。「どんな情報をどんな粒度で入れるか」「いらない情報とそうでない情報をどう分けるか」。ここが、第二の脳の一番大事なところだね。
ベクトルDB選定は「リサーチエージェント」に任せる — Claude Codeの真価
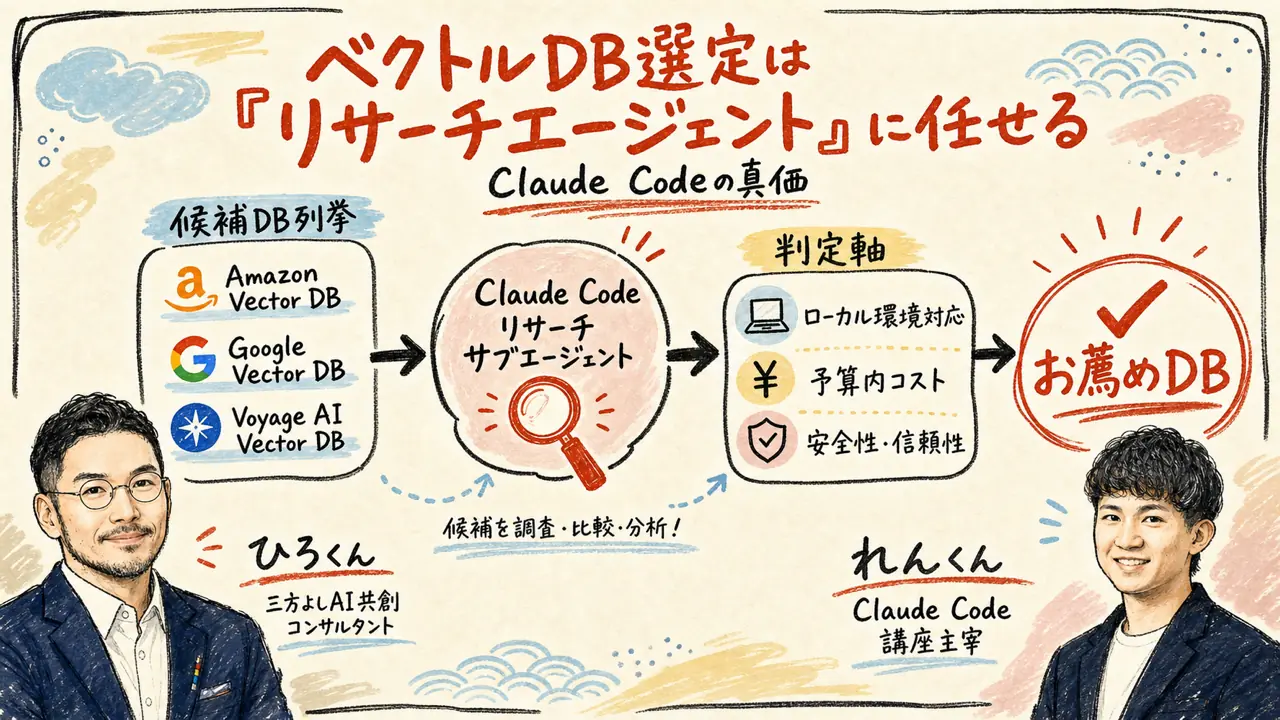
「どのベクトルDBを使えばいいんだろう」。これは、Claude Codeを触り始めた人が必ずぶつかる壁だ。Amazon Bedrock、Google Vertex AI、Pinecone、Chroma、Voyage AI……選択肢が多すぎて、何から比較すればいいかも分からない。
れんくんが提示した答えは明快だった。「Claude Codeにリサーチエージェントを作らせて、徹底的にリサーチさせる」。自分で調べようとするから迷う。AIに調べさせれば、条件を設定するだけでいい。
れんくん
「Claude Codeにリサーチエージェントというのを作って、徹底的にリサーチをさせる。そのサブエージェントが自分のローカルの現状と、予算やスピードや安全性を考慮して、リサーチした結果に基づいておすすめしてくれる」
具体的には、リサーチエージェントに以下の条件を渡す。今自分が持っているファイルの量と種類。予算の上限。処理スピードの要件。セキュリティや安全性の要件。これらを踏まえて、最適なベクトルDBをAIが提案し、さらに設定まで行ってくれる。
これがClaude Codeの「真価」だと私は感じている。ChatGPTやGeminiでも情報は調べられる。しかし「じゃあこういうふうにやるといいですよ」と言ったとき、SQLを打ったり英語だらけのログイン画面を操作したりといった実作業まで、Claude Codeはやってくれる。
ひろくん
「GPTやGeminiは調べてくれるけど、じゃあこういうふうにやったらいいですよって言ったとき、英語ばかりのページにログインして何しているのか絶対分からないよ。SQLを打ってください、とか分からないじゃん。これの大半はやってくれちゃうというのがある」
リサーチエージェントの概念は、ベクトルDB選定だけに留まらない。これは「調べる仕事をAIに外注する」という思考法の転換だ。かつて「調べる」は人間の仕事だった。しかしClaude Codeが登場してから、調べる仕事はAIが担い、人間は「何を調べさせるか」「どんな条件で評価するか」を決めることに集中できるようになった。
私の場合、Claude Code実践会でも同様の事例を紹介した。CCブースターというシステムを作り、Claude Codeを開いてコピペするだけで、AI秘書が質問を通じて自分専用の分身AIと「第二の脳」の改版を完成させてくれる。これも本質的には「リサーチと設計をAIに委ねる」という同じ発想だ。
ベクトルDB選定は、だいたいこんな流れになる。まず現在の情報資産の棚卸しをAIに依頼する。ファイルの数、種類、総文字数、更新頻度などを自動で調べさせる。次に、それらを踏まえた選定基準を設定する。コスト、スピード、セキュリティ、スケーラビリティ。最後に、Claude Codeに複数のDB候補を比較させ、推薦を受けて承認する。承認したら、設定・移行もClaude Codeが行う。
この一連のプロセスで、人間がやることは「何を重視するか」を判断することだけだ。これが一人社長にとって、いかに価値があるか。時間という有限なリソースを、意思決定に集中できる。
RAG活用事例1: コンテンツ生成とマーケットイン発信
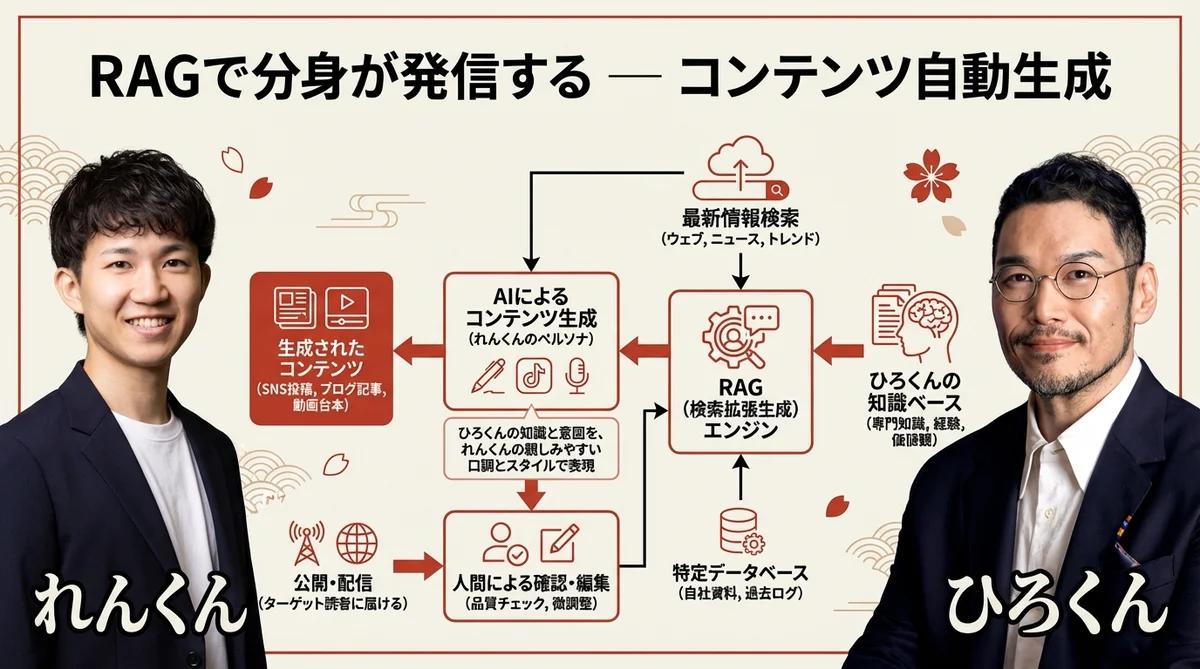
ベクトルDB(RAG)を構築したとして、それをどう使うのか。「作って満足」では意味がない。れんくんが紹介してくれたのが、コンテンツ生成への活用事例だ。これが実に具体的で、一人社長がすぐに真似できる内容だった。
れんくんは自身の「ナレッジ一覧」というウェブアプリを構築し、その裏側をベクトルDBで運用している。YouTube配信の文字起こし、勉強会の内容、日々の発信——これらをすべてベクトルDBに蓄積する。そして、そのデータベースをもとに、コンテンツを生成する。
れんくん
「自分の生の情報をどれだけデータベースにできるかが肝。生データができれば、そこからX、YouTube、スレッズ、ブログの発信を自分の分身が発信してくれる状態を作れる」
「プロダクトアウト」と「マーケットイン」の違いを意識しておきたい。自分が話したいことだけを話すと、コンテンツは大量に作れても見られない。市場が何を求めているかをリサーチして、自分の生データと掛け合わせたコンテンツを作れば、見られる確率が格段に上がる。
れんくんが作ったYouTube分析サービスは、この考えを体現したツールだ。今どのテーマが市場で熱いか、どんな動画が注目を集めているかを分析する。さらに、そのツール自体をAIが操作できる形にしている。AIがリサーチし、自分の生データと掛け合わせて、マーケットインのコンテンツを自動生成する。
れんくん
「YouTubeの分析ツールをAIが操作できる形にしておくと、自分の生データとリサーチの結果を元に掛け合わせてマーケットインのコンテンツが作られてくる。自分の分身がパワーアップした状態でコンテンツを作っていける」
これを聞いた私の感想は「手足が生えた状態になる」だった。分身AIが自分の代わりにリサーチし、データを見て、コンテンツを作る。アドレス指定(ターゲットに最適化した)コンテンツができてしまう感覚だ。
一人社長がコンテンツ発信を続ける上での最大の課題は「ネタ切れ」と「市場とのズレ」だ。自分の中からだけ発想すると、どうしても偏りが生まれる。しかし自分の生データとリサーチを組み合わせれば、ネタは枯渇せず、かつ市場ニーズに刺さるコンテンツが生まれ続ける。
ここで注目したいのが、AIが「プロデューサー」の役割を担い始めるという変化だ。かつてコンテンツのプロデュースは、経験豊富な人間が担うものだった。市場のトレンドを読み、発信者の強みを引き出し、見せ方を決める。Claude Codeはそれを、一人社長でも実現できるレベルで提供し始めている。
私が運営するGPTs研究会でも、このマーケットインの発想は非常に重要視している。7,300名以上のメンバーが集まる中で、「何が求められているか」を常にリサーチし、それに対応したコンテンツを提供することが、グループの活性化に直結しているからだ。第二の脳を使ったコンテンツ生成は、このプロセスを格段に効率化する。
RAG活用事例2: 会社のブレインを作る — マニュアル・議事録・プロジェクト管理
れんくん(15:06〜)
「なので自分の頭だけじゃなくて自分の分身だけじゃなくてその自分の分身がよりパワーアップした状態でコンテンツを作っていける。これめちゃくちゃすごくないですか?」
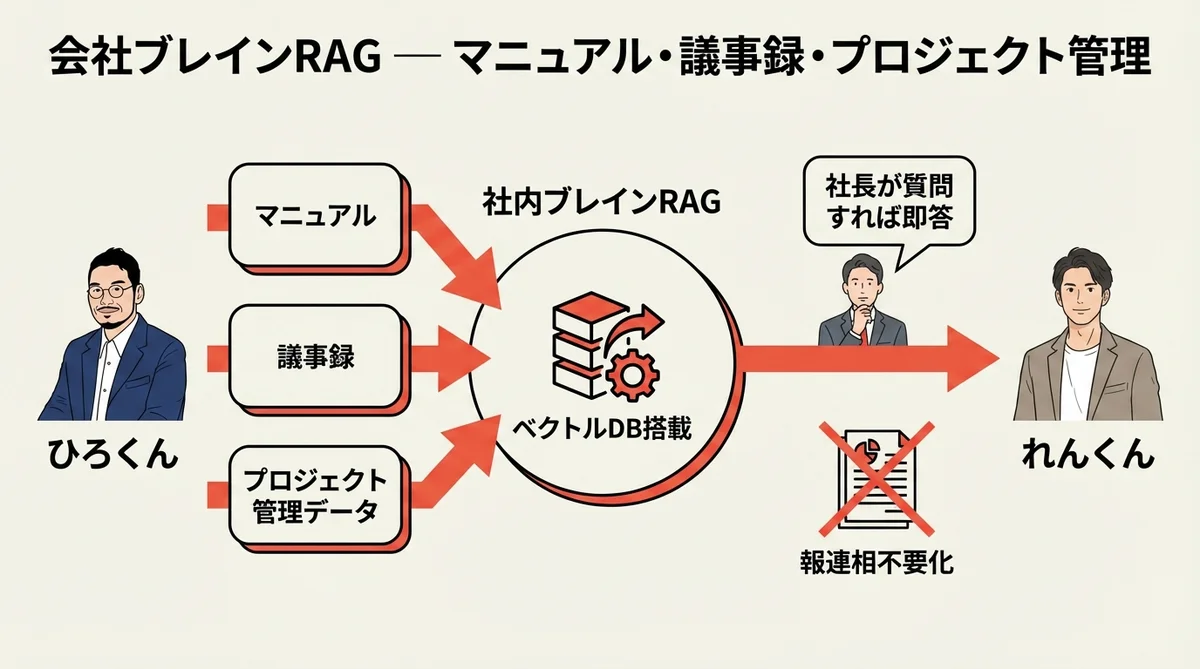
RAGのもう一つの活用軸が、「会社のブレイン」を作ることだ。コンテンツ生成がアウトプット側だとすれば、こちらは組織・経営の内部インフラとしての活用だ。マニュアル、議事録、プロジェクトの進捗——これらをベクトルDBに蓄積することで、社長が自ら「どうだったっけ?」と記憶を辿る必要がなくなる。
れんくん
「プロジェクトごとの議事録がそこにまとまっているので、社長が報告・連絡・相談をしなくても、そのRAGに聞けば返答が返ってきてプロジェクト管理がスムーズにいく」
私自身、このライブもそうだが、Zoomもすべて録画したものを自動的に文字起こしし、ナレッジに入れている。その際、話者分離も行っている。誰がいつ何を言ったかを一言単位でベクトルDBに入れておく、という形だ。
ひろくん
「自分と人の意見が混じらないし、以前との変化も分かる。新しいプロジェクトでも、過去にこういうふうにやり取りしていた人の履歴が残っているから、まさに自分がちゃんと思い出しながら考えたかのごとく、しかもより良いものがものすごいスピードで出来上がってくる」
「話者分離」というのは、発言録を単に全体テキストとして保存するのではなく、「誰が何を言ったか」を分離してDBに格納することだ。これにより、特定の人物の発言だけを検索したり、複数回の会議にわたる特定のテーマの議論を追跡したりすることが可能になる。
れんくんもこの点を補足してくれた。ZoomはVTT拡張子でテキスト情報をダウンロードできる。そもそも話者分離された状態でダウンロードしてくれるケースもある。Google MeetもアカウントごとにAI議事録として取得できる。ミーティングツールに応じて、話者分離・保存・ベクトルDB投入というフローを設計すればよい。
この「会社のブレイン」という概念の持つ意味は非常に大きい。一人社長にとって、最も時間を奪われる作業の一つが「思い出す」ことだ。「あのプロジェクト、何で止まったんだっけ?」「あのお客さん、どういう経緯で来てくれたんだっけ?」こうした「思い出す」という無意識の作業に、実は膨大な時間が奪われている。
会社のブレインが整っていれば、これらの問いを「第二の脳」に聞けばいい。AIが過去のデータを参照して、整理された形で答えてくれる。しかも、感情や先入観なく、事実ベースで。これは経営判断のクオリティを根本から変える。
もう一点、気をつけたいのが「入れ方」だ。れんくんが指摘したように、ベクトルDBは「入れれば入れるほどいい」ではない。ゴミが入れば、ゴミが出てくる。何をどんな粒度で、どのカテゴリーで入れるかを考えておく必要がある。コンテンツRAG、議事録RAG、マニュアルRAG——用途別に分けて管理していくといい。
複数のRAGを横串で刺す — 0→1のひらめきを生むAI脳
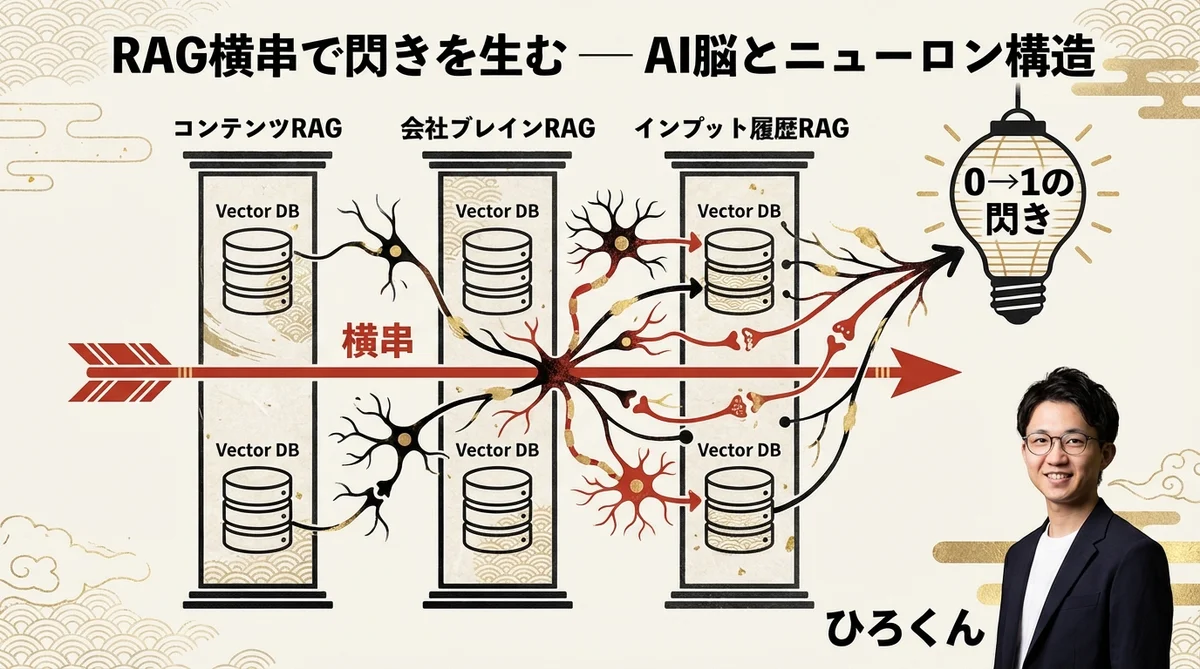
このセクションは、この対談で最も深く、最も刺激的な話題だった。複数のRAGを横串で刺す——それによって、「0→1のひらめき」が生まれるかもしれない、という問いかけだ。
現在のAIは、「0→1の企画力」が弱いとよく言われる。AIに「新しいビジネスアイデアを出して」と言っても、どこか既視感のある、無難な答えが返ってくることが多い。れんくん自身、この問いを長く持ち続けてきた。
れんくん
「別々に作ったRAGを横串刺して横断させて、このひらめきを埋めないかというのを今トライしている。自分の生データ、リサーチ結果、日々喋っている内容の文字起こし、記事録を読み込んで……それらを組み合わせた時に、RAGを相互に横串で刺すことで、0→1のひらめきが生まれるんじゃないか」
このアイデアの理論的根拠が、ディープラーニングとニューラルネットワークの起源だ。人工知能の基礎となるニューラルネットワークは、人間の脳のニューロン・シナプス構造を模倣して設計された。脳の中で「ひらめき」が生まれるのは、異なる記憶が偶発的に結びついた瞬間だと言われている。
れんくん
「脳科学のところを発展させてディープラーニング・ニューラルネットワークという構造にAIを起こしている。その今のRAGを組み合わせて0→1を埋めないか。脳の構造を理解した上で、この閃き・ピンときた感覚をデータを元にできないか」
私はこれを聞いて、深く共鳴した。AIと人間の脳は、構造として非常に似ている。「ハルシネーション(幻覚)をするし、記憶は上書きされるし、ゼロイチじゃない」——人間だって同じじゃないか、という感覚がある。人間こそ「単純じゃない」は言えるのか、という問いかけだ。
ひろくん
「AIに言えないなって思うくらい、自分もミスばかりするし。脳を模してAIは作られてきているから、人間がどうやってアイディアを着想するかというところで、全く関係ない衝突というか、ひらめきという部分って、そういうので偶発的に生まれてくる。むしろ逆にAIの方が得意じゃないかと思う」
この「偶発的な交差」という概念が鍵だ。人間の脳も、全く関係ないと思っていた記憶同士が、ある瞬間に結びついてひらめきが生まれる。RAGを複数持ち、それを横断させることで、AIでも同じことが起きるのではないか。コンテンツRAG × 議事録RAG × インプットRAGを横断させたとき、どんな「偶発的な交差」が起きるか。
れんくんの見立ては明快だ。「AIが0→1の企画を埋めていないのは、圧倒的にデータの集約が足りないだけ」。どんなステークホルダーがいて、どんなプロジェクトが走っていて、どんな関係性があるか——それを全部読み込ませることができたら、AIのひらめきが人間を超えうる。
れんくん
「AIが0→1の企画を埋めていないのは圧倒的にデータの集約が足りないだけ。Claude Codeに自分の情報、どういうステークホルダーがいてどういうプロジェクトが走っているかを全部読み込ませることができたら、AIのひらめきのほうが圧倒的に勝てそう」
これは、私が4年間「分身AI」の開発を続けてきた中で感じていることと、完全に一致する。外見の分身から始まり、中身の分身へ。ナレッジを入れ、共感ストーリーを入れ、コンテキストを精緻化していく。それでも「ひらめき」の部分だけは、まだ人間に依存していた。しかし、複数のRAGを横断させるという設計によって、そのひらめきすらAIが生み出せるようになるかもしれない。
「入れれば入れるほどいいわけではない」と言いながら、「しかし、インプットの量と種類が増えれば、AIの精度は人間を超えうる」という逆説。この矛盾の解決策が、RAGの設計思想だ。ゴミは入れない。しかし、関連する情報は幅広く、深く蓄積する。そして複数のRAGを横断させることで、異なる情報領域が偶発的に交差する確率を高める。これが、AI脳の「育て方」だ。
FAQ
よくある質問
ひろくん(15:18〜)
「いや、すごい。あの、やっぱそのなんだろうまさに手足が生えた状態になるわけだよね。本当になんだろう。実際見に行ってデータ見てある意味アドレスじゃんけんができちゃうみたいな状態だもんね」
マークダウンファイルとベクトルデータベース、どちらを選ぶべき?
LIVEではれんくんが「マークダウンは10万20万100万文字になるとAIが読みすぎてバカになる」って話してくれたんだよね。だから小規模なうちは.mdで十分だけど、ファイルが増えてAIが重くなってきたらベクトルDBへ移すタイミングかな。選び方で迷うところは、自分で比較せずにClaude Codeにリサーチエージェントを作らせちゃう——これがれんくんの推しだったよ。
RAG(ラグ)とは何?初心者でも作れる?
Retrieval-Augmented Generation の略で、AIが外部データベースを検索して答えるしくみのこと。LIVE中にも話したけど、私が一番うま味だなって思ったのは、SQLや英語のログイン画面を自分で触らなくても、Claude Codeに自然言語で頼めば構築から運用までやってくれるところ。「英語ばかりのページにログインして何してるか分からない」みたいなのを、ほぼ肩代わりしてくれるんだよね。
複数のRAGを組み合わせると「0→1の閃き」が本当に生まれる?
これはまだ仮説段階。れんくんが今トライしてる話で、私もこの対談で初めて聞いて「面白い」って思ったんだよね。人間の脳のニューロン構造がディープラーニングの元になったように、別々のRAGを横串で刺すと情報が偶発的に交差して閃きが生まれるんじゃないか、っていう。れんくんは「AIが0→1を埋められないのは、データの集約が足りないだけ」って言ってた。答えが出たら、またLIVEで報告するね。
れんくんと話してみて、頭の中で残ってるのは「ベクトルDBはClaude Codeに作らせて選ばせちゃう」っていう発想が衝撃的だったこと。自分で比較すると迷うところを、リサーチエージェントに丸ごと渡しちゃう。これ、ちょっと真似してみたいなって思った。
あと、複数のRAGを横串で刺すと0→1のひらめきが生まれるかも、っていう問いかけが面白かったな。れんくんが「データの集約が足りないだけ」って言ってたのが妙に頭に残ってる。答えはまだ出てない。
私の方は「AIに言えないなって思うくらい、自分もミスばかりするし」って話したよね。AIと人間って、けっこう似てるんだなって、れんくんと話してて改めて思った。このへんの話、もっと深掘りしていきたいな。
COLUMN
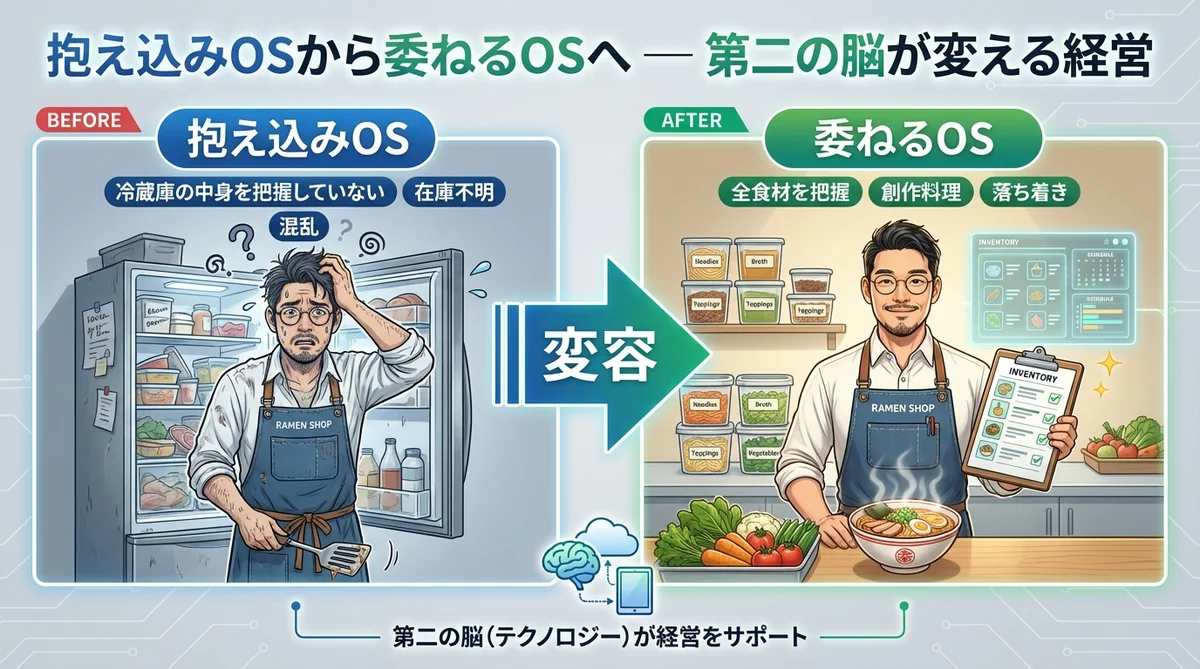
抱え込みOSから委ねるOSへ — 第二の脳が変える経営の景色
一人社長で経営してると、ある時期から「全部知ってる自分」がしんどくなってくるんだよね。「これは自分しか分からない」「自分が覚えてなきゃ」——そういう気持ちが、いつのまにか経営のスピードを落としてた気がする。料理で言えば、鍋をかき回しながら、冷蔵庫の中身も把握して、来週の献立も考えてる状態。それで美味しい料理ができるかっていうと、なかなか難しいよね。
れんくんと話してて、第二の脳って「抱え込みOS」から「委ねるOS」へのスイッチなんだなって改めて思った。過去の会議もプロジェクトの経緯も顧客とのやり取りも、ベクトルDBに入れておけば「覚えてなきゃ」っていう重荷がなくなる。覚える脳が軽くなると、考える脳のほうが動き出すんだよね。
分身AIを4年やってきて感じるのは、「委ねる」のにもちょっとコツがいるってこと。ただ情報をAIに渡せばいいわけじゃなくて、どの情報をどんな粒度で、どのカテゴリーに入れるか。れんくんも「ゴミが入ればゴミが出てくる」って言ってたよね。冷蔵庫の中身を把握した料理人になるには、まず冷蔵庫の整理からなんだなって。
関連記事: AIの品質チェックは仕組みが9割。分身AIの失敗談から学ぶプロセス改善|分身AI日記 DAY51
今、私が面白がってやってるのが、RAGを複数持って横断させる「閃きのエンジン」。れんくんが話してた、コンテンツRAG・議事録RAG・インプットRAGが横串で刺さると、別々の情報が偶発的に交差する——人間の脳でひらめきが生まれるのと同じ構造かも、っていう話。答えはまだ分からないけど、データの集約量の問題なんじゃないかなって、今は感じてる。
「委ねるOS」への切り替えって、信頼の話でもあるよね。自分の判断の根拠になるデータをAIに預けて、その分析に乗っかって動く。「全部自分でやる」が長かった人ほど、これはけっこう大きな心の動きだと思う。でも一回委ねてみると、時間の使い方がまるっと変わる。今の私にとっては、第二の脳はもう便利ツールっていうより、経営の土台みたいなものになってるな。
分身AI.comで、詳しく解説しています
bunshin-ai.com — 分身AIひろくんの知識と実践ノウハウを集約したメディア。AIに仕事を委ねる技術を、事例とともに学べます。
RELATED
🎁 れんくんの公式LINE(Remotionテンプレ30種プレゼント)
動画で紹介された全30種類のRemotionテロップテンプレートを無料でお届け。登録するとシナリオが流れてくるよ。
📱 れんくんの公式LINEに登録関連記事
- 週刊GPTs研究会|routines×Agent Teams・分身AIに魂を宿す・Claude Code別物進化(2026年4月3週)
- Claude Opus 4.7&Canva AI 2.0登場?デザイン革命到来【最新AIニュース解説】2026年4月17日号
- LLMO対策とは?田中紗代が教えるAI検索時代の集客術
関連記事(Claude Code関連・分身AI関連・AI経営関連)はこちらに挿入されます。
REFERENCES
参考リンク
Claude Code 公式ドキュメント — Anthropic
docs.claude.com — Claude Codeの使い方・APIリファレンス・最新アップデート
Anthropic Claude — 公式サイト
anthropic.com — Claudeの概要・プラン・APIアクセスに関する公式情報
分身AI.com — 分身AIひろくんの実践メディア
bunshin-ai.com — 第二の脳・分身AI・AI経営の実践ノウハウ
GPTs研究会 — Facebookグループ
facebook.com/groups/gptslabo — 7,300名突破!毎週月曜13時コラボLIVEも開催中
JOIN US
一緒にAI経営を学びませんか?
無料メルマガでは、LIVE配信の内容をさらに深掘りした記事・ツール情報をお届けしています。また、GPTs研究会Facebookグループでは、7,300名以上のメンバーと一緒に毎週月曜13時のコラボLIVEを楽しめます。
LIVE INFO
この配信について
| 配信日 | 2026年4月6日(月)13:00〜 |
| テーマ | 第二の脳をClaude Codeで構築!一人社長のAI経営術 |
| 出演者 | 田中啓之(ひろくん)× 戸野塚レン(れんくん) |
| チャンネル | AI氣道 @AIKIDO-GPTs |
| 動画URL | youtube.com/watch?v=LsZjrORzvnY |
🎁 無料プレゼント
Aiport(ClaudeCode AIエージェント実践会)
ClaudeCodeでAI秘書+分身AI+AIカンパニーが無料で作れるキット&解説動画をプレゼント!
▶ 無料で入会してキットを受け取る🤖 AI生成コンテンツについて
この記事はAIツール(Claude Code)を活用して制作しています。構成・文章生成・画像制作にAIを使用し、最終的な内容の確認・編集・公開判断はひろくん(田中啓之)本人が行っています。「分身AIひろくん」(bunshin-ai.com)とは別のコンテンツです。


