AIツール活用
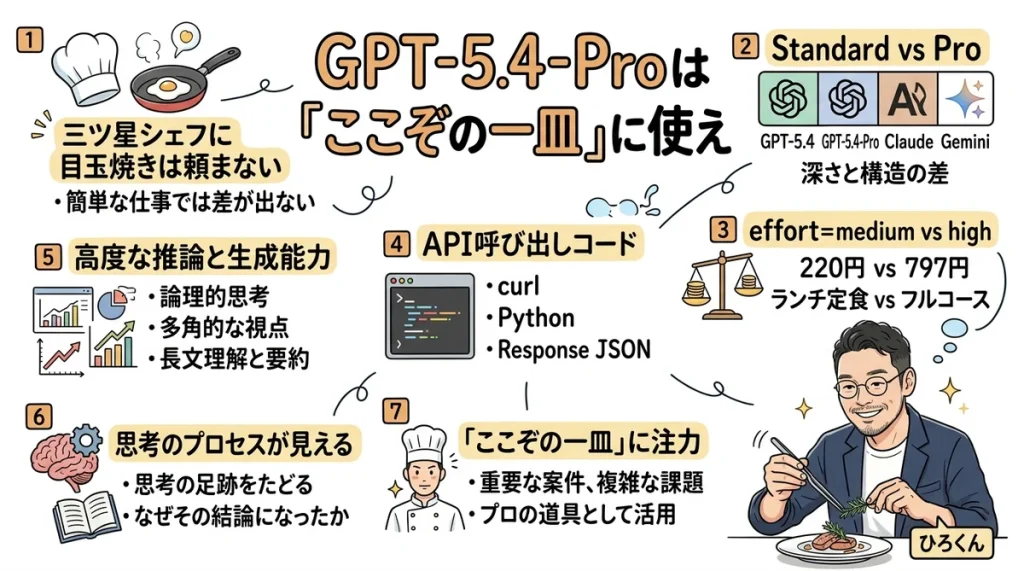
GPT-5.4-Proは「ここぞの一皿」に使え——effort比較データで見る、最上位モデルの正しい使い方
2026年3月8日
家事と子育てのスキマで経営する3方よしAI共創コンサルタントの田中啓之、ひろくん(@passion_tanaka)です。
この記事でわかること
- GPT-5.4-Proは普通の質問では差が出ない。どんなタスクで真価を発揮するのか
- effort=medium vs highの処理時間・トークン数・コスト・品質を実データで比較
- Responses APIの実際の呼び出しコード(curl / Python)
- マルチLLMシステムでの組み込み方(私のチーム運用事例)
- 月額4,000円前後で使いこなすコスト設計
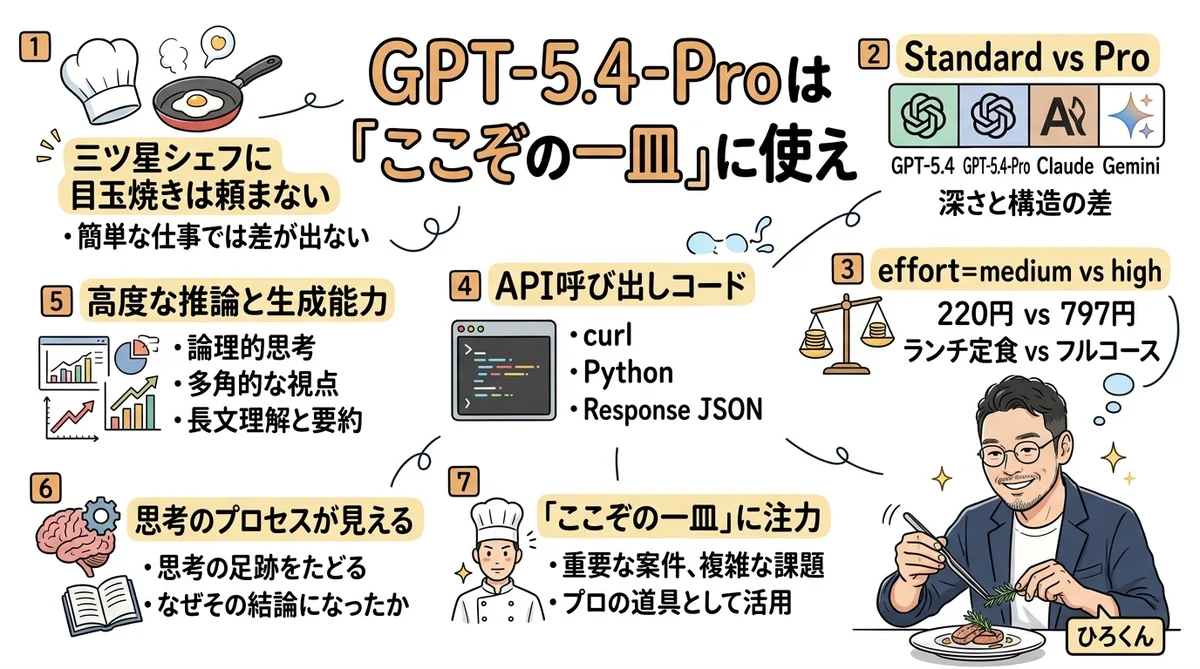
まず結論:GPT-5.4-Proは「簡単なお願い」では差が出ない

最初にはっきり言います。
GPT-5.4-Proに「AIについて教えてください」と聞いても、StandardモデルのGPT-5.4と変わりません。
私は実際に同じプロンプトをGPT-5.1、5.2、5.4(Standard)、5.4-Proに投げて比較検証しました。たとえば、以下のようなリード文作成の依頼です。
40代の会社員で副業を始めたい人向けに、AIを使った副業の始め方の記事の導入文を書いてください。条件:300文字以内、読者の悩みへの共感から始める、具体的な数字を1つ入れる、最後に記事を読むメリットを1文で伝える、煽りや誇張は使わない
結果は……4モデルともほぼ同じクオリティでした。
🍳 料理で例えると
GPT-5.4-Proは「三ツ星シェフに目玉焼きを頼んだ」ようなもの。目玉焼きは誰が焼いてもほぼ同じ。三ツ星の腕が光るのは、フルコースの設計や、複数の味のバランスを同時に取る料理なんです。
では、どんなタスクならProの差が出るのか。ここから具体的に見ていきます。
Standard vs Pro:4モデル比較で見えた「差が出る境界線」

差が出ないタスク
| タスクの種類 | 5.1 | 5.2 | 5.4 | 5.4-Pro |
|---|---|---|---|---|
| 制約付き短文(リード文等) | ○ | ○ | ○ | ○ |
| 知識ベースの質問 | ○ | ○ | ○ | ○ |
| 箇条書きの要約 | ○ | ○ | ○ | ○ |
どのモデルでも十分な品質が出ます。ここにProの料金を払う意味はありません。
差が「はっきり出る」タスク
次のプロンプトで4モデルを比較しました。
「効率を追求すればするほど、かえって非効率になる」——この逆説が成立する具体例を3つ挙げ、それぞれメカニズムを分析し、最後に「本当の効率とは何か」をあなた独自の定義で述べてください。
| 評価軸 | GPT-5.1 | GPT-5.2 | GPT-5.4 | GPT-5.4-Pro |
|---|---|---|---|---|
| 具体例の独自性 | 工場の稼働率(教科書的) | 会議短縮(日常的) | 技術的負債(専門的) | 技術的負債+組織設計+意思決定の3層(構造的) |
| 分析の深さ | メカニズムを説明 | メカニズム+対比 | メカニズム+比喩で圧縮 | メカニズム+因果連鎖+反転条件まで網羅 |
| 独自の定義 | 「総損失の最小化」 | 「削る技術ではなく残す見極め」 | 「壊れず、戻らず、続けられる形で進むこと」 | 複数の視点を統合した多層的定義 |
| 文字数と密度 | 約2,490字 | 約2,480字 | 約2,390字(最少で高密度) | 約8,000字(圧倒的な深さと構造) |
5.4-Proの違いは「深さ」と「構造」です。
5.4(Standard)は1つの切り口を研ぎ澄ます力に優れています。一方、5.4-Proは複数の切り口を同時に走らせ、それらを1つの構造に統合する力が桁違いです。
🍳 料理で例えると
「一品料理の完成度」と「フルコースの構成力」の違い。一品なら5.4で十分。でも、前菜からデザートまでの流れを設計し、味のバランスを通貫させるには、Proの思考力が必要です。
effort=medium vs high:実データで見るスイートスポット

GPT-5.4-ProのAPIには reasoning.effort というパラメータがあります。これはモデルが「どれだけ深く考えるか」を制御するもので、medium・high・xhigh の3段階です。
私は同じプロンプトで medium と high を比較しました。結果がこちらです。
比較データ(2026年3月9日実施)
| 項目 | effort=medium | effort=high |
|---|---|---|
| 処理時間 | 約400秒(6分40秒) | 約690秒(11分30秒) |
| 推論トークン数 | 7,033 | 25,383 |
| 出力トークン数 | 8,037 | 29,475 |
| コスト | 約220円($1.47) | 約797円($5.32) |
| 品質 | 実用十分。チーム配置提案5つ+月額コスト試算 | 圧倒的。90日戦略文書(Phase設計・週次カレンダー・KPI・ボトルネック分析) |
medium(220円)で得られたもの
AIチーム体制の配置提案を5パターン出し、それぞれの月額コスト試算まで付けてくれました。日常の意思決定には十分な深さです。
high(797円)で得られたもの
90日間のデイリー動画パイプライン戦略として、以下を一気に出力してくれました。
- 4フェーズのロードマップ(各Phase14〜28日の具体施策)
- 週7本のコンテンツカレンダー(曜日別のシリーズ設計)
- 8つの技術的ボトルネックと解決策
- 3つの差別化戦略(IP化・翻訳・公開実験)
- 5つのKPIと計測方法
29,475トークン(約12,000字)の戦略文書が、1回の呼び出しで完成しました。
結論:mediumがスイートスポット
| 用途 | 推奨effort | 理由 |
|---|---|---|
| 日常の判断・意思決定 | medium | 220円で十分な深さ。コスパが圧倒的 |
| 大型戦略文書・事業設計 | high | 797円だが、コンサルに依頼すれば数十万円の内容 |
| 簡単な質問・要約 | Proを使わない | Standard(5.4)やGeminiで十分 |
🍳 料理で例えると
mediumは「ランチのコース」。highは「特別な日のフルコース」。毎日フルコースを食べる必要はないけど、ここぞという時には一皿800円で三ツ星の味が出せる。これがGPT-5.4-Proの本質的な価値です。
実際のAPI呼び出しコード
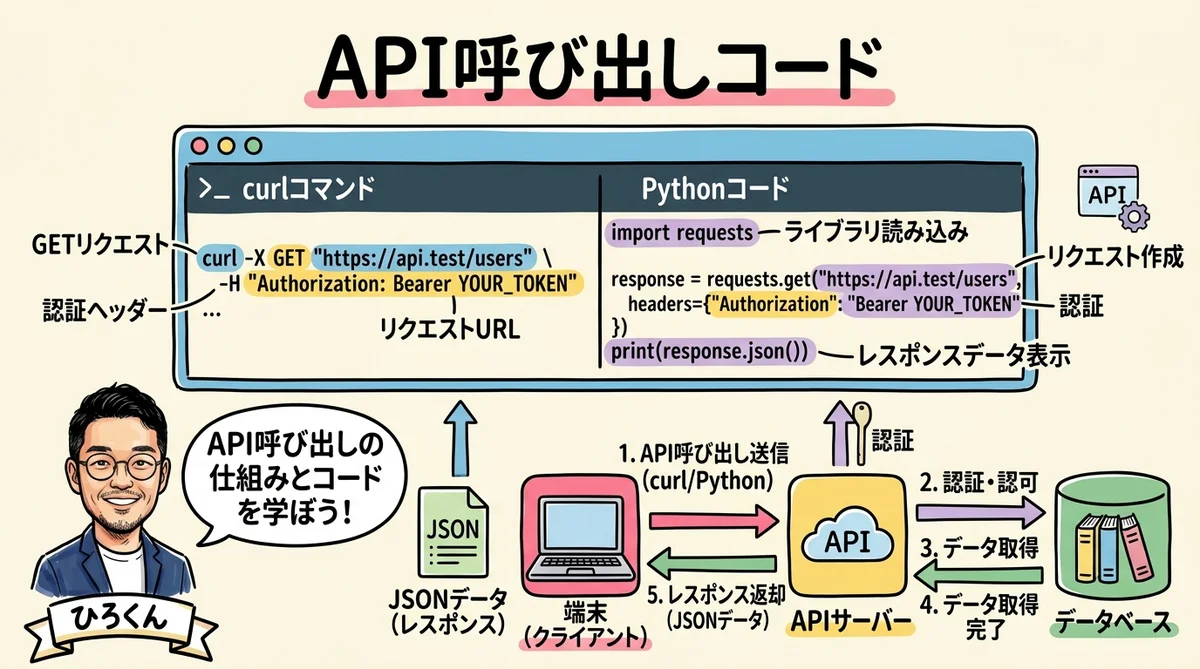
GPT-5.4-ProはResponses APIのみ対応です。従来の /v1/chat/completions では呼び出せません。ここは注意が必要です。
curlでの呼び出し
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5.4-pro",
"input": "あなたの事業の90日戦略を設計してください。Phase分割、週次カレンダー、KPIを含めること。",
"reasoning": {
"effort": "medium"
}
}'Pythonでの呼び出し
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.4-pro",
input="あなたの事業の90日戦略を設計してください。",
reasoning={"effort": "medium"},
)
# テキスト取得
text = response.output_text # 公式推奨のヘルパー
print(text)
# トークン使用量
print(f"Input: {response.usage.input_tokens}")
print(f"Output: {response.usage.output_tokens}")料金体系
| 項目 | 料金(1Mトークンあたり) |
|---|---|
| Input | $30(約4,500円) |
| Output | $180(約27,000円) |
| コンテキスト上限 | 1Mトークン |
Outputの方が6倍高いので、effort=high で大量の推論+出力が走ると一気にコストが上がります。だからこそ、effortの使い分けが重要なんです。
マルチLLMシステムへの組み込み方——私のチーム運用事例
私はGPT-5.4-Proを単体で使っていません。複数のLLMを役割分担させた「AIチーム体制」の中に組み込んでいます。
私のLLMチーム配置
| 役割 | モデル | 使い方 |
|---|---|---|
| 司令塔・品質管理 | Claude Opus | 判断・ルーティング・最終チェック |
| コード実装 | Codex(GPT系) | コーディング・デバッグ |
| 文章生成 | Gemini Pro | ブログ記事・長文ドラフト |
| 軽量タスク | GLM-5 | テンプレート処理・軽いテキスト生成 |
| 戦略設計 | GPT-5.4-Pro | 月3〜5回、ここぞの戦略文書 |
| 日常の質問 | GPT-5.4(Standard) | 比較検証・アイデア出し |
なぜProを「チームの一員」として使うのか
Proの出力は「素材」として優秀ですが、そのまま使うには長すぎたり、文脈に合わない部分もあります。だから、こういうフローで使っています。
1. Proに戦略文書を出力させる(effort=medium or high)
2. Claudeに品質チェックさせる(矛盾・抜け漏れ・実現可能性)
3. Geminiにブログ記事として整形させる(読みやすさの最適化)
4. 人間(私)が最終判断する(これでいくか、修正するか)🍳 料理で例えると
Proは「最高の食材を仕入れる市場」。食材がどれだけ良くても、仕込み・調理・盛り付けは別の作業。だから、仕入れ(Pro)→仕込み(Claude)→調理(Gemini)→盛り付け(人間)という分業が効くんです。
使い分けガイド:Proを使うべきタスク vs 他モデルでいいタスク
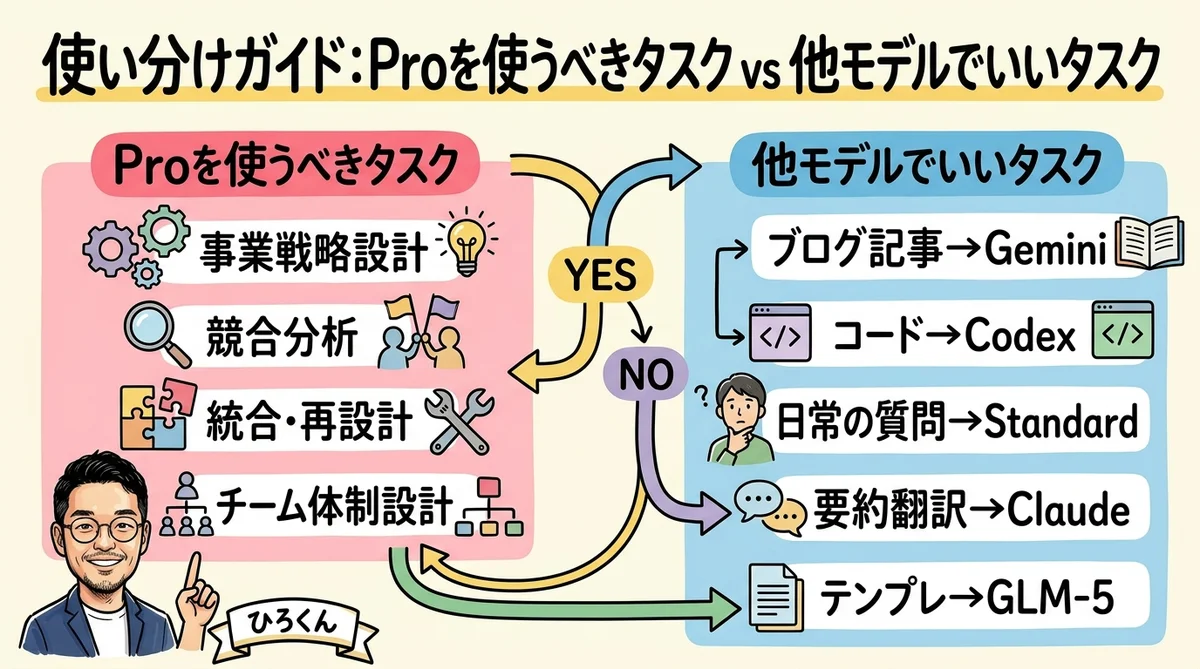
GPT-5.4-Proを使うべきタスク
| タスク | なぜProか | effort |
|---|---|---|
| 事業戦略の設計(90日〜1年) | 複数のPhaseとKPIを同時に設計する構造力 | high |
| 競合分析と差別化戦略 | 多軸比較と因果連鎖の分析力 | medium〜high |
| 既存施策の統合・再設計 | 矛盾する要素のバランス設計 | medium |
| チーム体制・役割分担の設計 | 5〜10のポジションを同時に最適化 | medium |
| 複雑な意思決定の整理 | 判断基準の構造化と優先順位付け | medium |
GPT-5.4-Proを使わなくていいタスク
| タスク | 代替モデル | 理由 |
|---|---|---|
| ブログ記事のドラフト | Gemini Pro | 文章生成はGeminiの方が効率的 |
| コード実装・デバッグ | Codex | コーディング特化モデルの方が精度が高い |
| 日常の質問・調べもの | GPT-5.4 Standard | Standardで十分。Proは過剰 |
| 要約・翻訳 | Gemini / Claude | 定型タスクにProのコストは不要 |
| テンプレ処理 | GLM-5 | 軽量モデルで0円〜数円で済む |
判断フローチャート
そのタスクは「複数の要素を同時に構造化」する必要がある?
├─ NO → Standard(5.4)またはGemini/Claudeで十分
└─ YES → 出力は3,000字以上になりそう?
├─ NO → effort=medium(220円)
└─ YES → effort=high(797円)コスト試算:月3〜5回Pro使用で月額いくらか
GPT-5.4-ProはAPI経由の従量課金で使えます。月額サブスクリプション(Pro: $200/月)に加入しなくても、APIキーさえあれば1回220円〜797円で同じモデルの恩恵を受けられます。月3〜5回の利用なら、月額2,000円前後で最上位モデルが使えるということです。
現実的な月間使用パターン
| 使い方 | 回数/月 | effort | 1回あたり | 月額 |
|---|---|---|---|---|
| 大型戦略文書 | 1回 | high | 約800円 | 800円 |
| 中型の意思決定 | 3回 | medium | 約220円 | 660円 |
| 比較検証・構造化 | 2回 | medium | 約220円 | 440円 |
| 合計 | 6回 | 約1,900円 |
月額約2,000円。高めに見積もっても月3,000〜4,000円です。
「高い」か「安い」かの判断基準
- 経営コンサルに同じ戦略文書を依頼したら → 数十万円〜数百万円
- ビジネス書1冊の知見を自分の事業に適用する時間 → 数日〜数週間
- GPT-5.4-Pro effort=highで同等の出力 → 797円、11分
「高い」と感じるなら、まだProが必要なタスクに出会っていない可能性があります。逆に、戦略設計を自分の頭だけで回している人にとっては、1回800円で「壁打ち相手+構造化+文書化」が全部済むのは破格です。
まとめ:GPT-5.4-Proは「毎日使うもの」ではなく「ここぞで使うもの」
| ポイント | 内容 |
|---|---|
| Proが必要なタスク | 複数要素の同時構造化、戦略設計、多軸比較 |
| Proが不要なタスク | 日常の質問、記事執筆、コーディング、要約 |
| effortの使い分け | medium(220円)が基本。high(797円)は大型戦略専用 |
| 月額コスト | 月3〜5回使用で2,000〜4,000円 |
| 最大の価値 | コンサル級の戦略文書が800円・11分で手に入る |
| API注意点 | Responses APIのみ対応。/chat/completionsは使えない |
GPT-5.4-Proを毎日の作業に使うのは、三ツ星シェフに毎朝の目玉焼きを頼むようなもの。もったいないし、差も出ません。
でも、事業の方向性を決める時、新しいプロジェクトの全体設計をする時、複数の選択肢を構造的に比較する時——そういう「ここぞの一皿」にProを使うと、他のモデルでは出せない深さと構造が返ってきます。
大事なのは、「何でもProに聞く」ではなく「Proに聞くべきことだけProに聞く」という使い分けです。
私の場合、日常は他のモデルに任せて、月に数回だけProを呼び出す。それだけで、事業の意思決定の質が明らかに変わりました。
最上位モデルの本当の使い方は、「最上位だから全部任せる」ではなく、「最上位でしか出せない価値を見極めて、そこだけ使う」こと。
GPT-5.4-Proは、そういう使い方をした時に、初めて本当の実力を見せてくれます。
関連記事